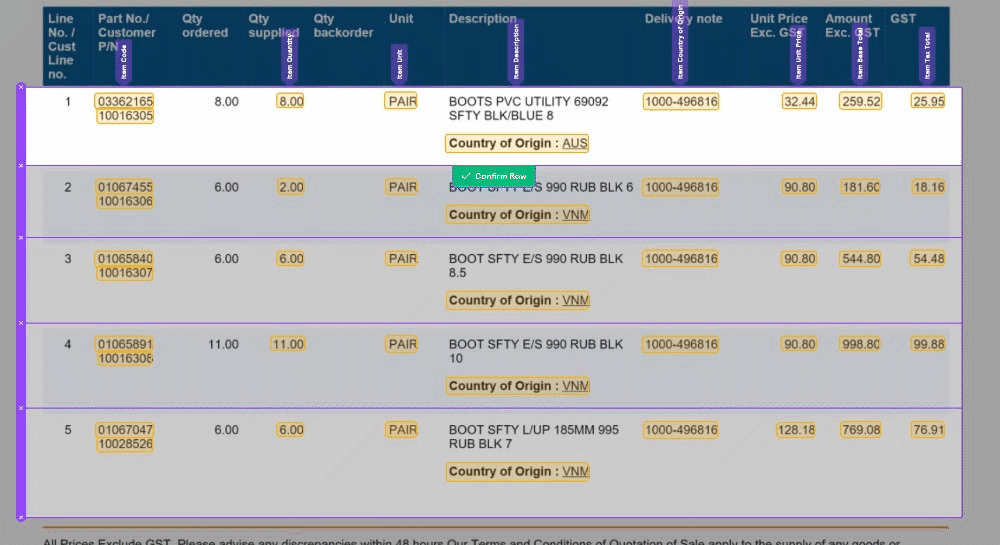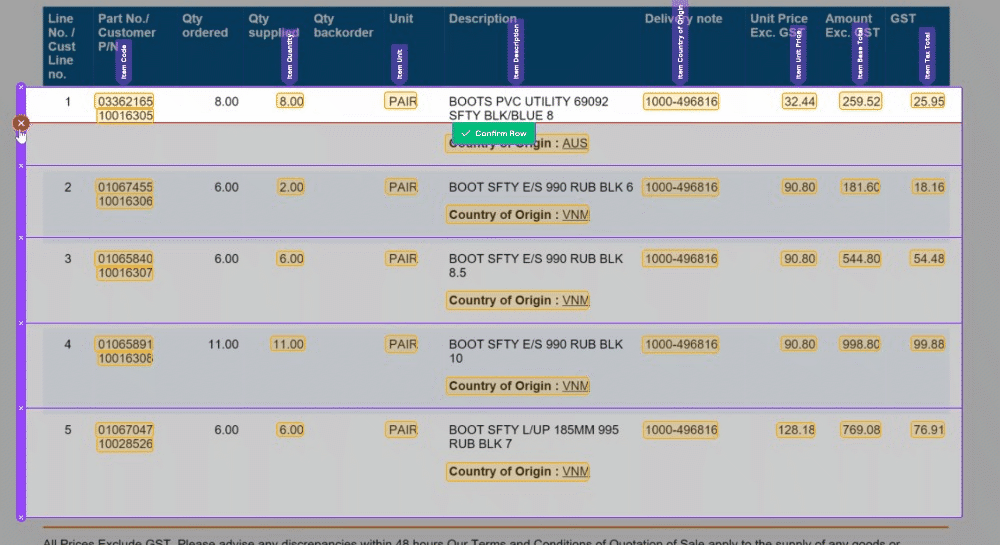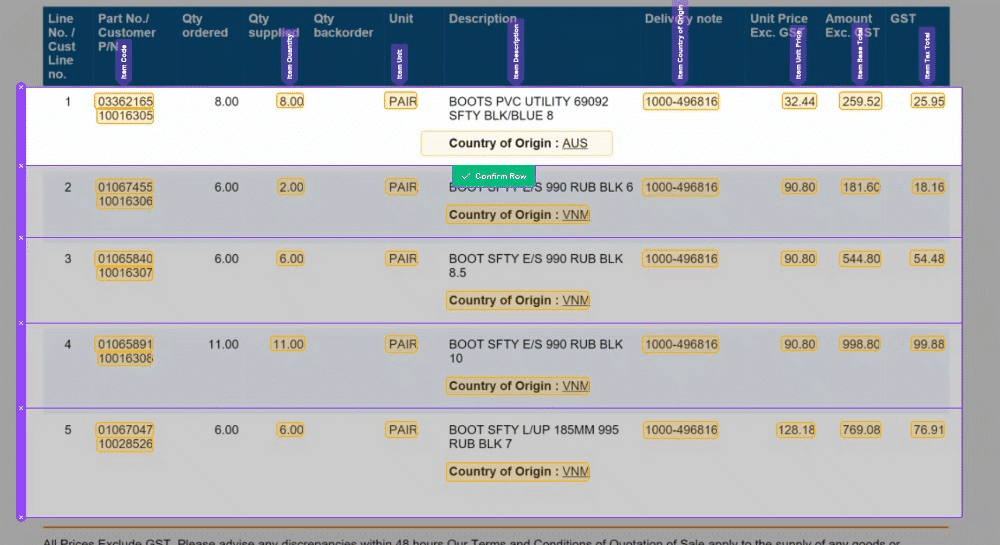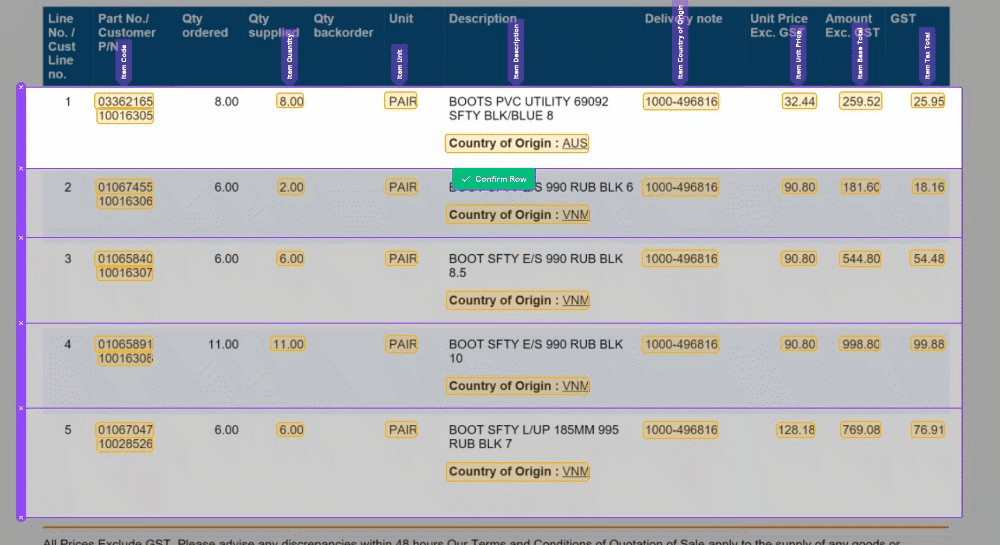
We've made some important improvements to our Magic Tables feature. These updates are all about making life easier. With these Magic Tables improvements, you can effortlessly capture nested or semi-structured data. It's a more stable and intuitive experience that empowers you to work with confidence.
Magic tables in 'beta' mode
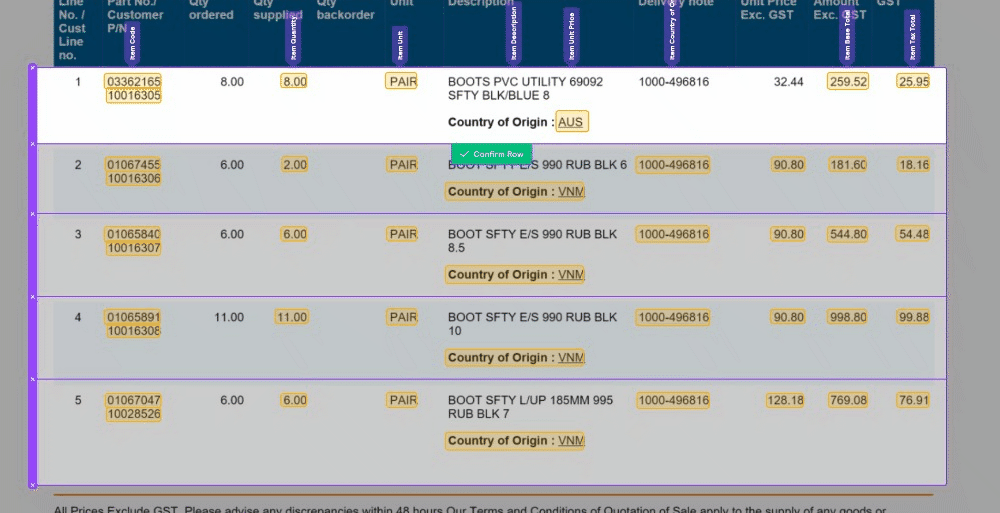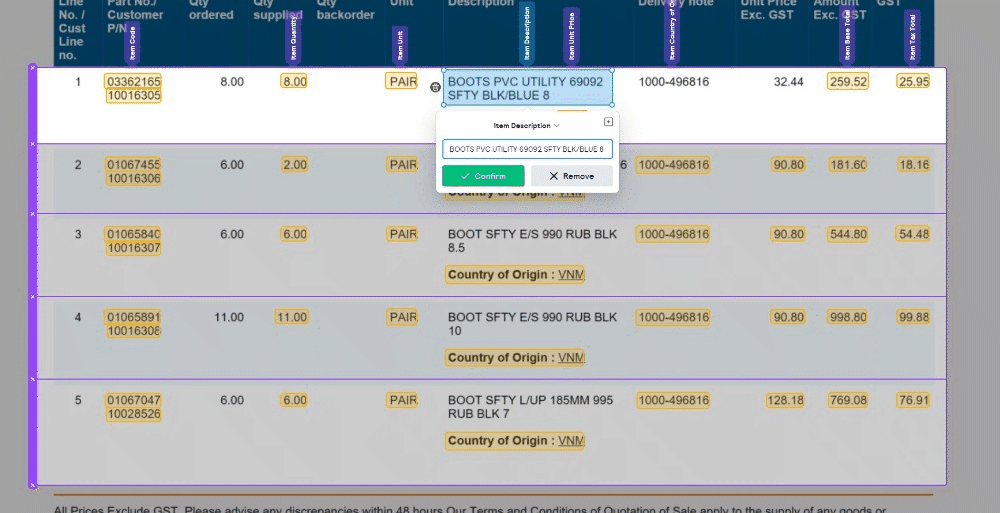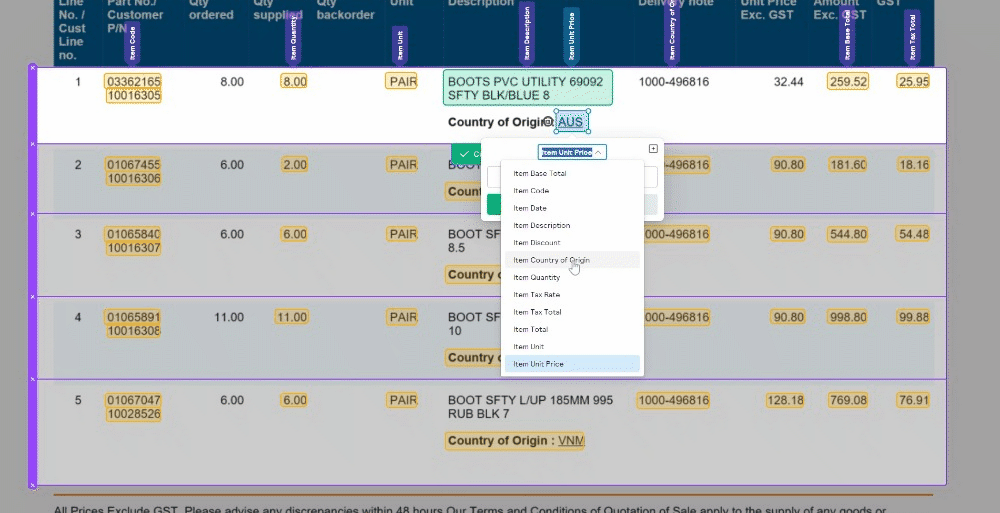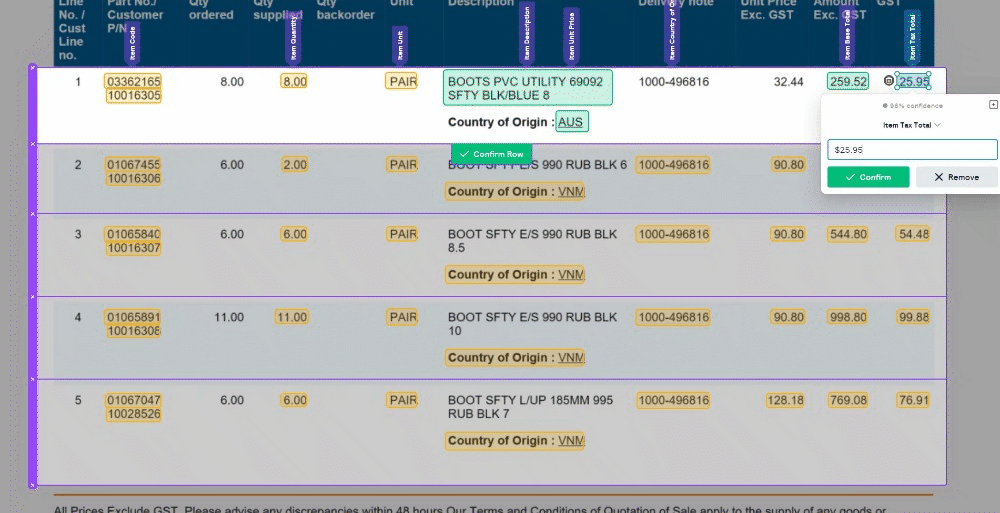
Magic Tables are still in beta mode for a full release as the standard option for invoice tables later this month. To enable these tables, update the field settings in your invoices Collection and enable 'Line Items (beta)' (disable the existing Line Items Field).
What's New in Magic Tables?
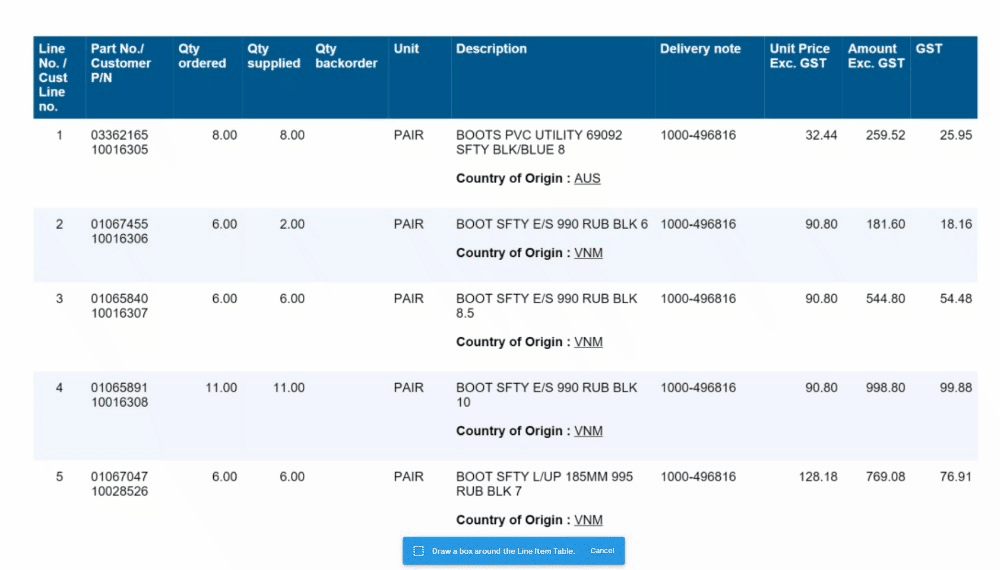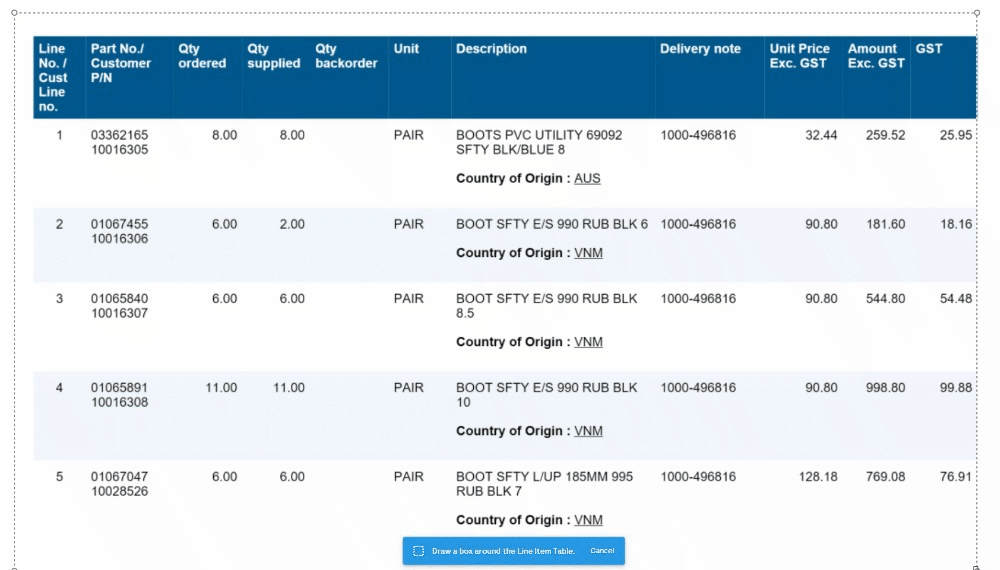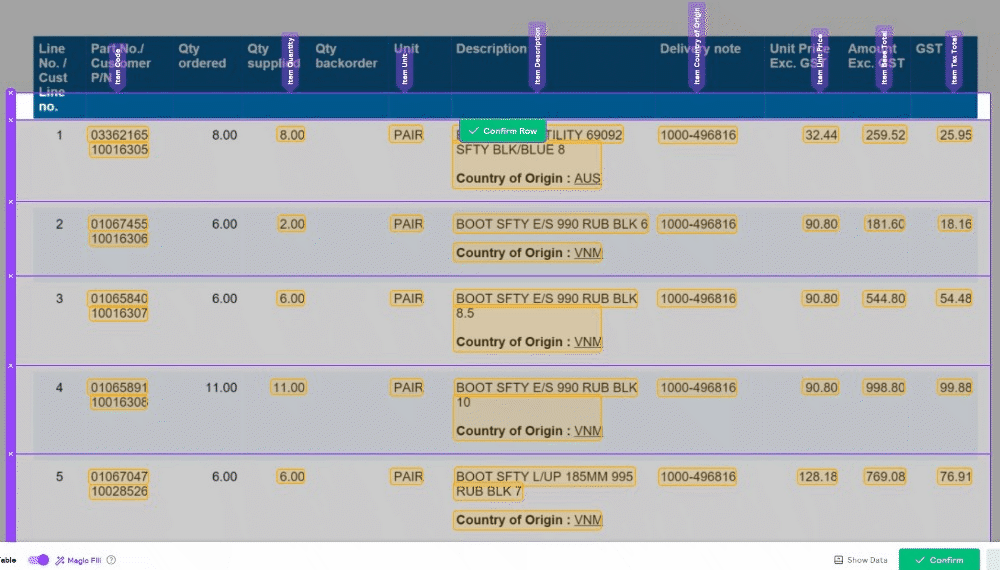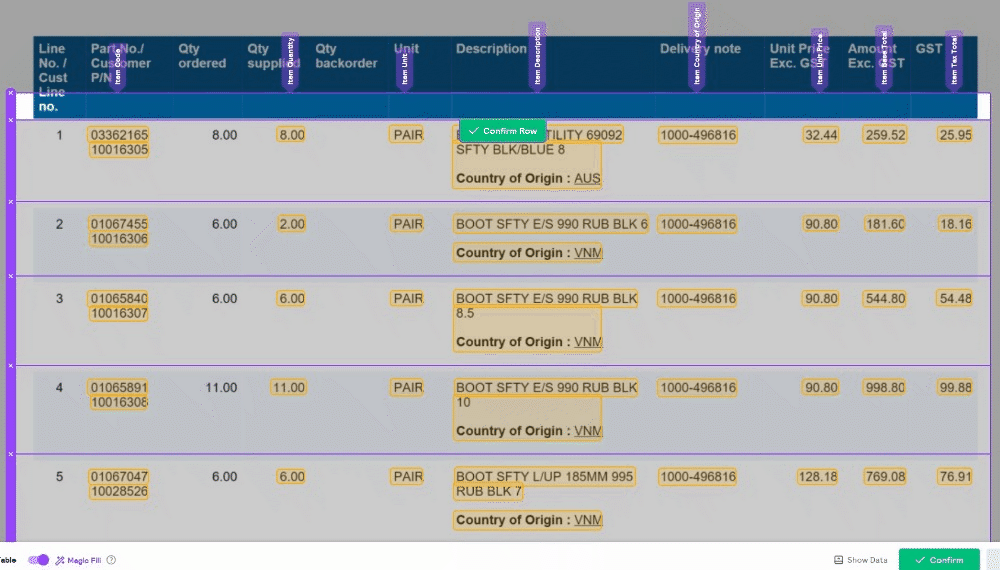
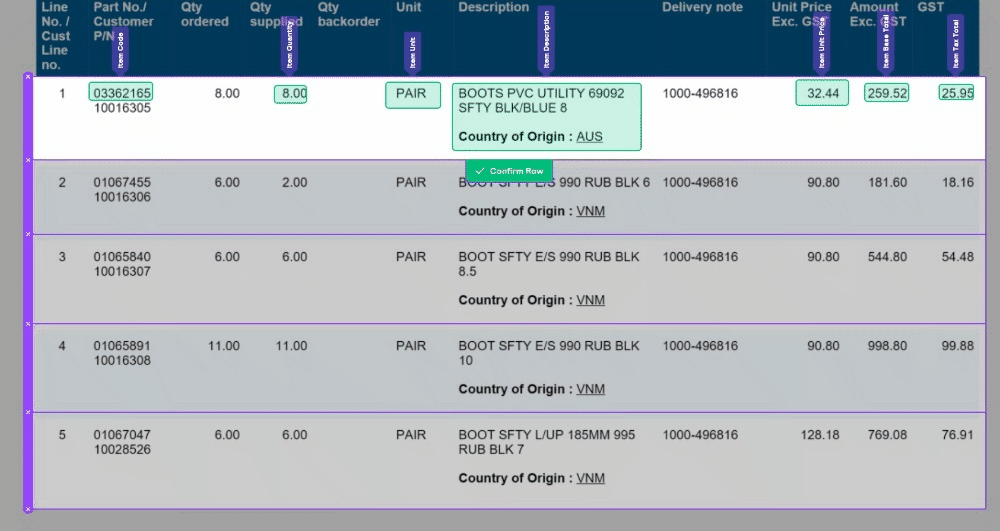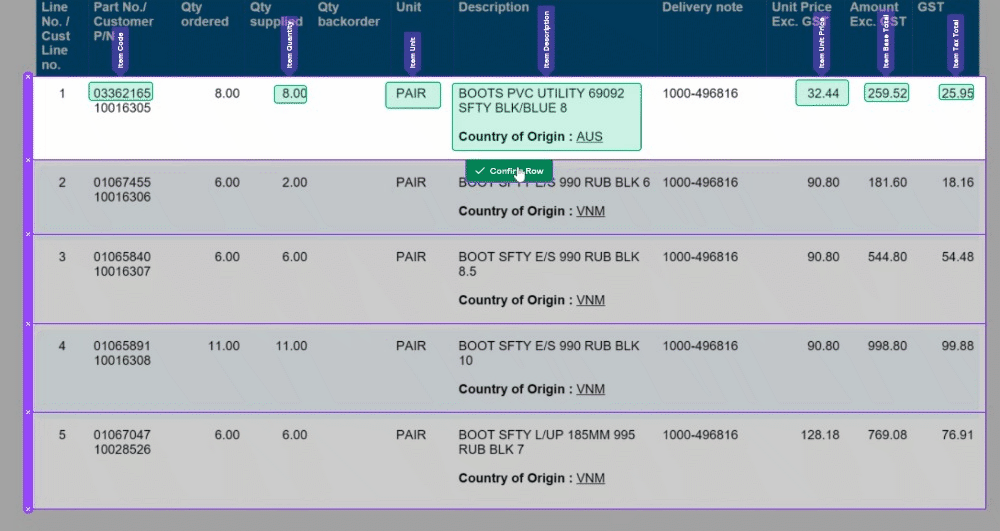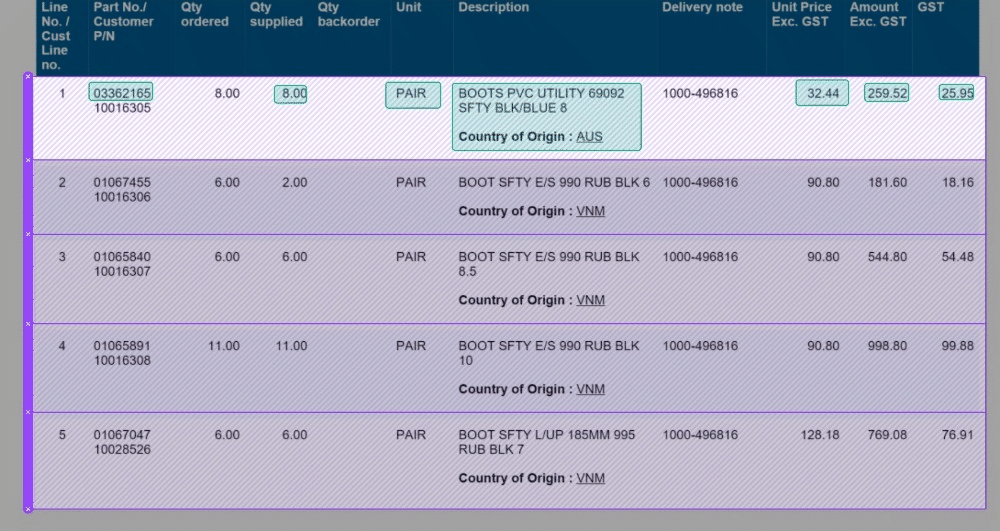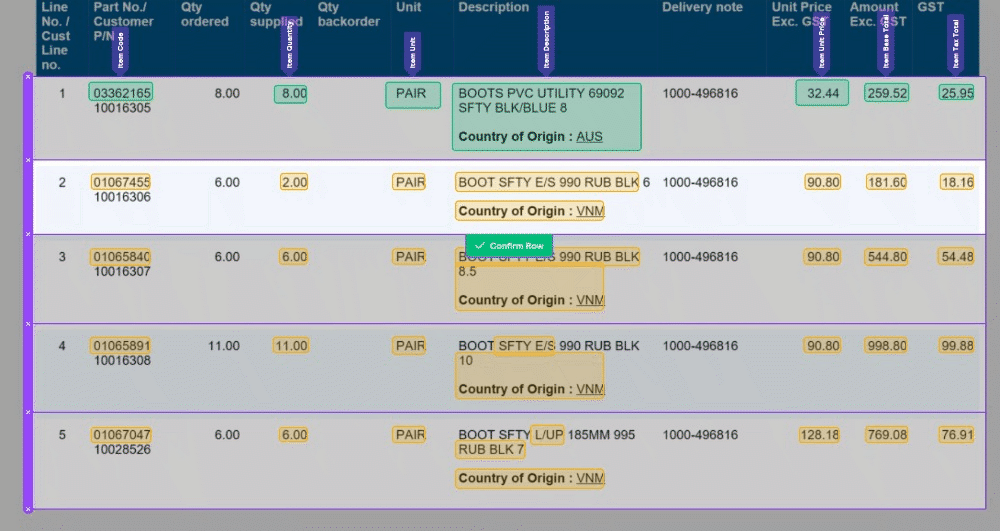
🧙♂️ 1. Enhanced Validation: We understand the importance of accuracy in your data. Now, with our improved Magic Tables, you'll be prompted to validate information row by row. This ensures that your data is accurate and error-free, providing you with more control and confidence in your work.
🔮 2. Magic Fill Control: We've made a significant change to 'Magic Fill.' It will now only be applied to rows below your current selection. This adjustment increases the stability of your data and minimizes unintended changes, giving you a smoother user experience.
🔀 3. Toggle 'Magic Fill': Your data, your control. We've added the ability to toggle 'Magic Fill' on and off, allowing you to decide when you want to harness the power of automation and when you prefer manual data entry. Flexibility at your fingertips!
📊 4. Improved Table Layout: We know how crucial screen space is when working with tables. That's why we've made the table output grid from the bottom hidden by default. This means more screen real estate for you to work with, making your tasks more comfortable and efficient.
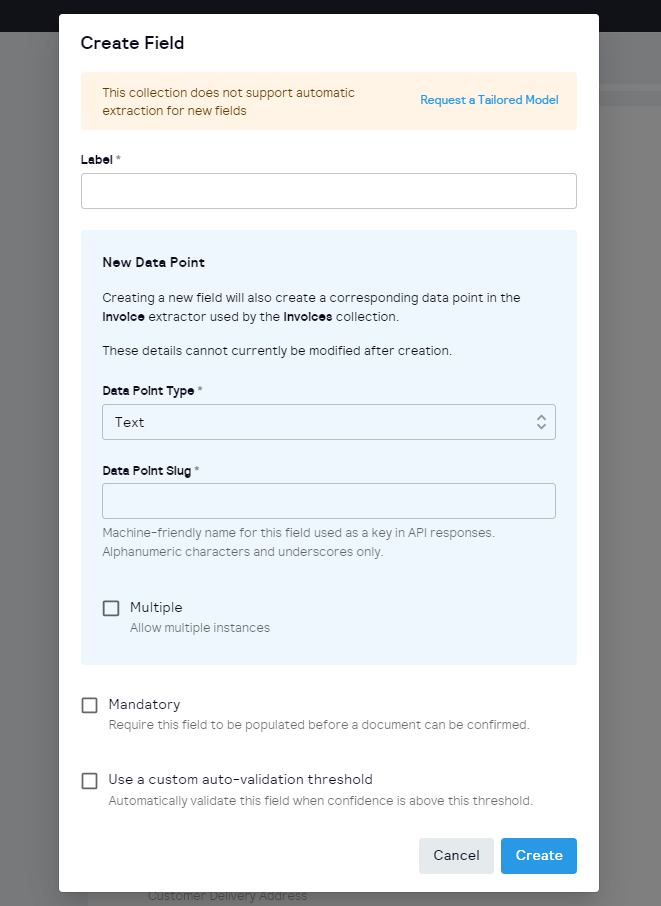
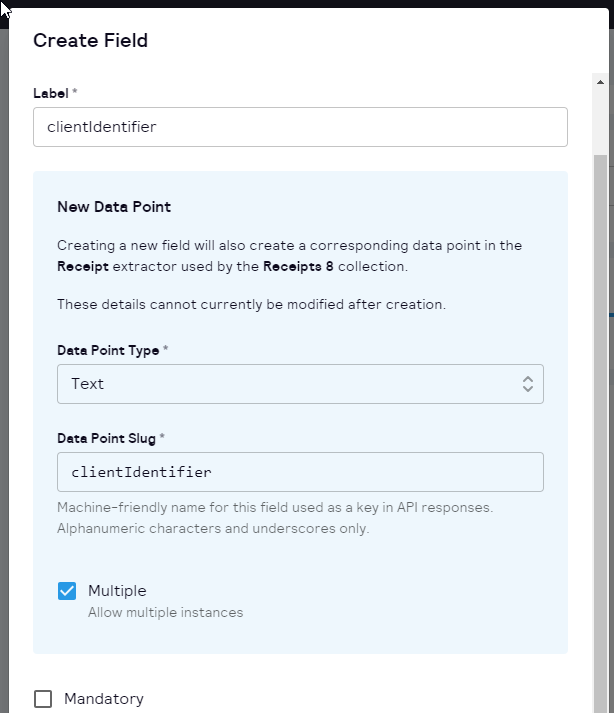
🔍 5. Consistent Field Editor: To create a seamless user experience, we've ensured that the Field Editor is now consistent with the rest of the UI. This makes navigating and editing your data fields a breeze.