Documentation Index
Fetch the complete documentation index at: https://docs.affinda.com/llms.txt
Use this file to discover all available pages before exploring further.
Recruitment Technology Product Suite
Affinda’s product suite for Recruitment Technology covers five complementary pre-built offerings. These products leverage our core technology and the data extracted from our industry-leading Resume Parser to deliver time-saving products to the recruitment industry.
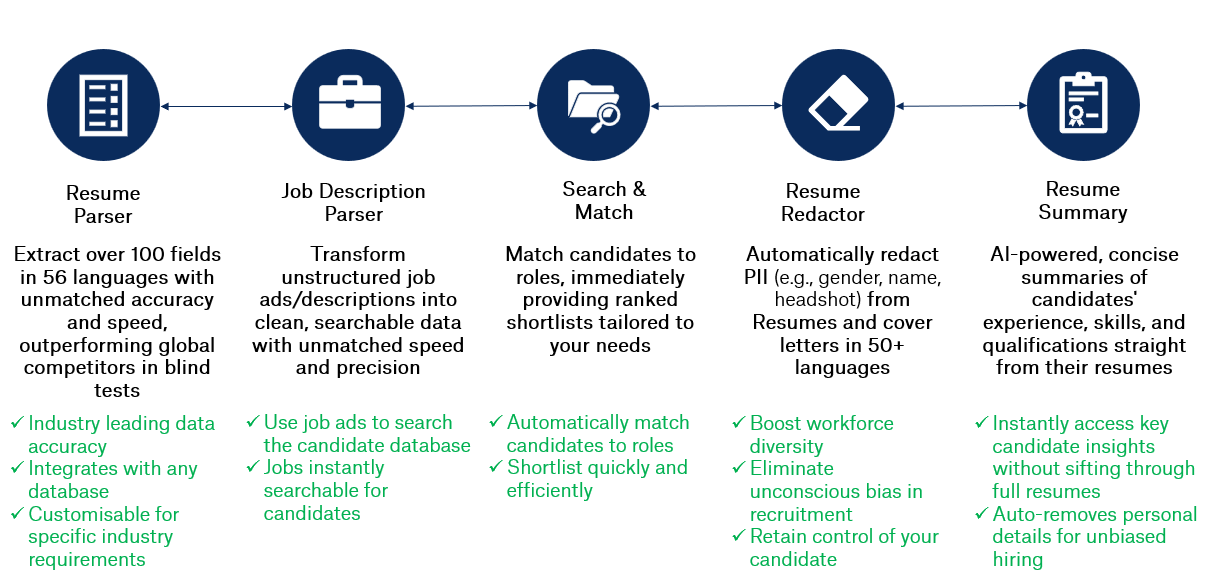
Getting Started
After creating your free trial and selecting ‘Resume Parsing’ as your use case, a Workspace specific to recruitment technology will be configured that contains all products in the suite for testing. This Workspace will be configured with:
- Classification disabled: Typically, Resume Parsing customers will know the document type they are processing, so they should upload directly to the Document Type (rather than to the Workspace and relying on Affinda classification). This will improve the speed and accuracy of parsing.
- Validation disabled: Disabling validation hides features (e.g. ‘Confirm Document’) that are typically used where there is a ‘human in the loop’ required to process documents.
The above settings can be enabled via Workflow settings.
Testing
Understanding the Affinda document interface
Affinda’s document interface provides a simple tool to visualise all of the outputs from the model. This means that customers can quickly assess the accuracy of the solution and all of the data that has been extracted. Customers can observe the raw values that have been extracted from the document, as well as the final ‘parsed’ values that have been formatted or mapped into standardised values that can be more easily used in downstream processing.
Updating visible fields
When first getting started, all fields extracted will be visible. However, often customers will only care about a subset of fields that Affinda extracts from resumes. To enhance the testing process, customers can ‘disable’ certain fields in our document interface by selecting ‘Configure Fields’ when viewing a document. These fields are then no longer visible in the user interface, so testing is restricted just to the fields that matter.
Additional data available in API response
While the Affinda document interface includes a wide range of data and provides a clear representation of model accuracy, additional data is available within the API response. This includes a wide range of metadata and both the raw and parsed values.
For the Resume Parser, additional data about specific fields not visible in the UI is also present, including Standard Occupation Classifications, structured location information, and additional details on websites, phone numbers, and other contact information. (See Data Extracted for an example output.)
We recommend that customers familiarise themselves with all of the data present in the API response as part of testing.
Inviting colleagues
For information on how to add colleagues to assist with testing, see User Management.