Recruitment Technology Product Suite
Affinda’s product suite for Recruitment Technology covers five complementary pre-built offerings. These products leverage our core technology and the data extracted from our industry-leading Resume Parser to deliver time-saving products to the recruitment industry.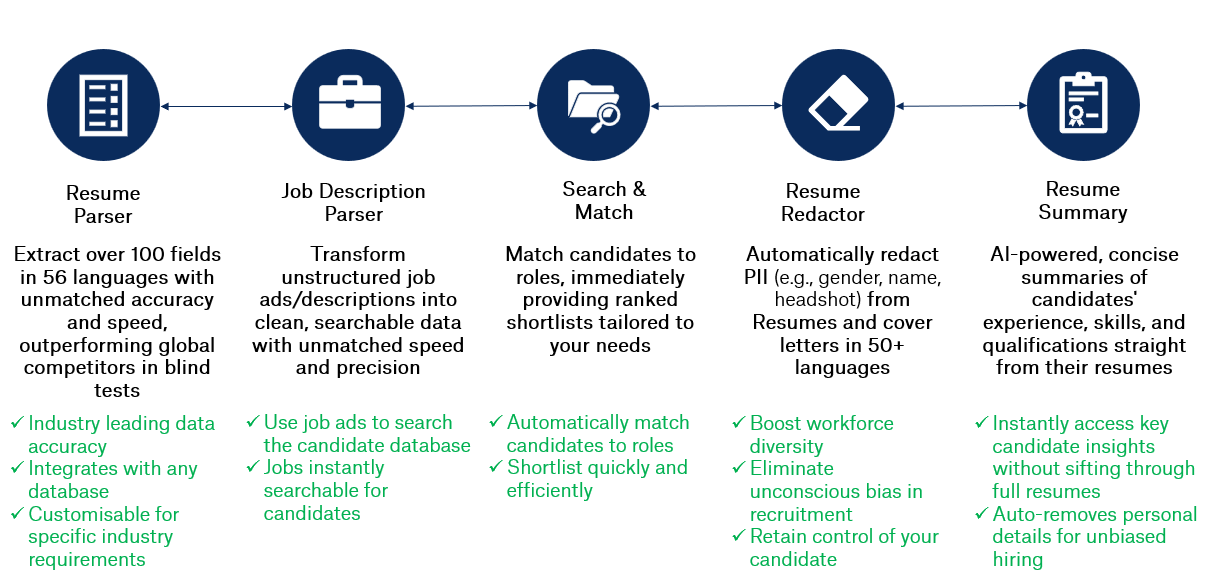
Getting Started
After creating your free trial and selecting ‘Resume Parsing’ as your use case, a Workspace specific to recruitment technology will be configured that contains all products in the suite for testing. This Workspace will be configured with:
- Classification disabled: Typically, Resume Parsing customers will know the document type they are processing, so they should upload directly to the Document Type (rather than to the Workspace and relying on Affinda classification). This will improve the speed and accuracy of parsing.
- Validation disabled: Disabling validation hides features (e.g. ‘Confirm Document’) that are typically used where there is a ‘human in the loop’ required to process documents.