We are delighted to announce some fantastic new features and enhancements to our validation tool that will take your experience to the next level!
What's New?
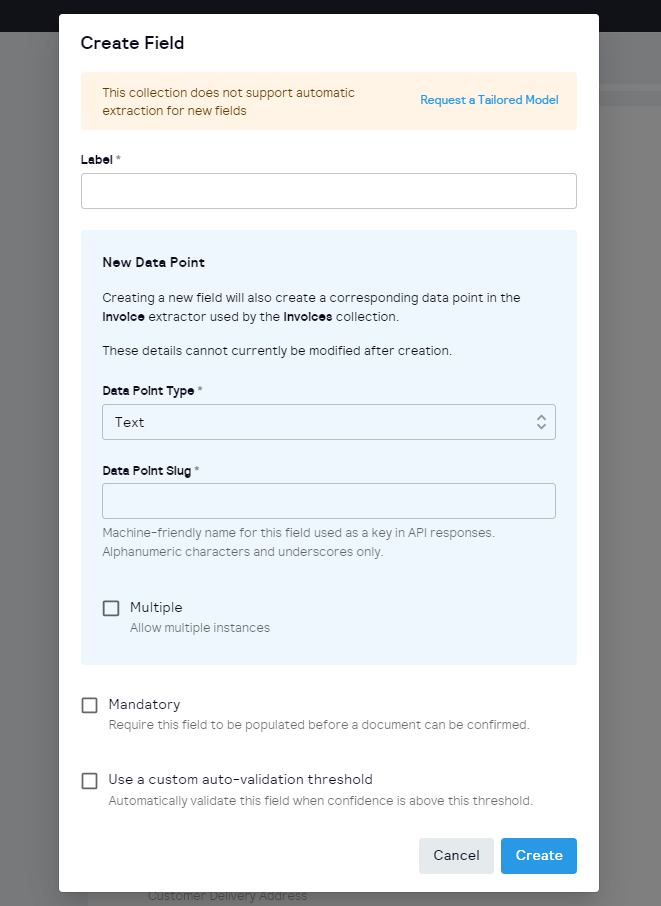
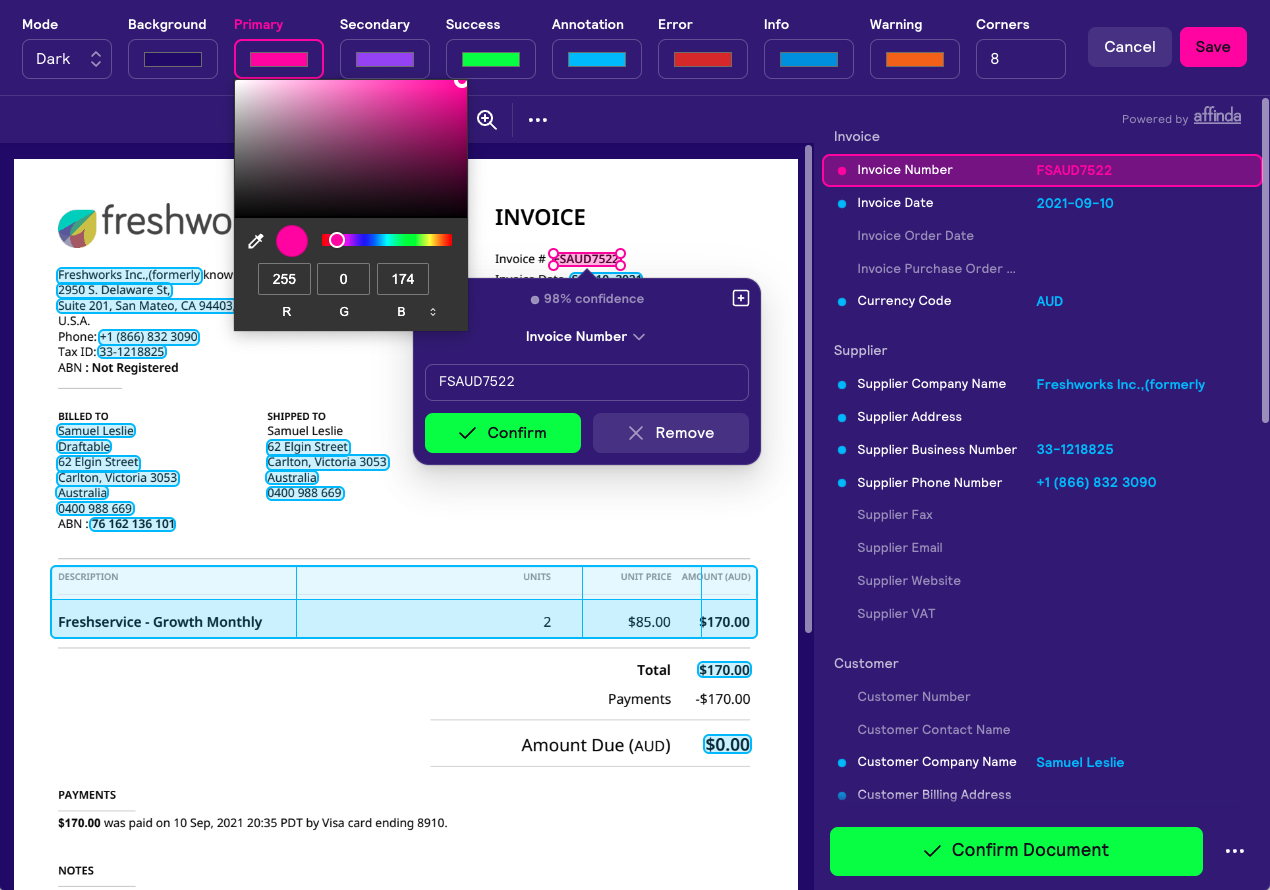
We have revamped our validation tool, adding new actions and reorganizing the layout to create a more user-friendly and efficient environment. Here's what you can now do with our improved tool:
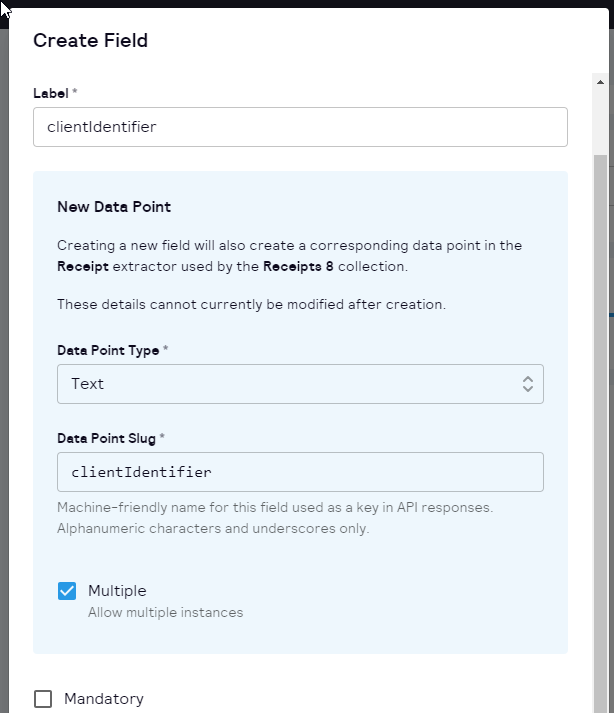
Rename a Document: You asked, and we listened! Now you have the ability to rename your documents directly within the validation tool.
Add Tags to a Document: Organizing and categorizing your documents is now a breeze. Our updated tool allows you to add relevant tags to your documents within the validation tool, making it easier to manage and search for specific files later on.
Export Document Data: We understand the importance of data accessibility. With this new functionality, you can now export document data directly from the validation tool, saving you valuable time and effort.
See Document Warnings: Stay informed and address potential issues proactively. Our latest update enables you to view document warnings, ensuring you are aware of any important concerns that may require your attention.
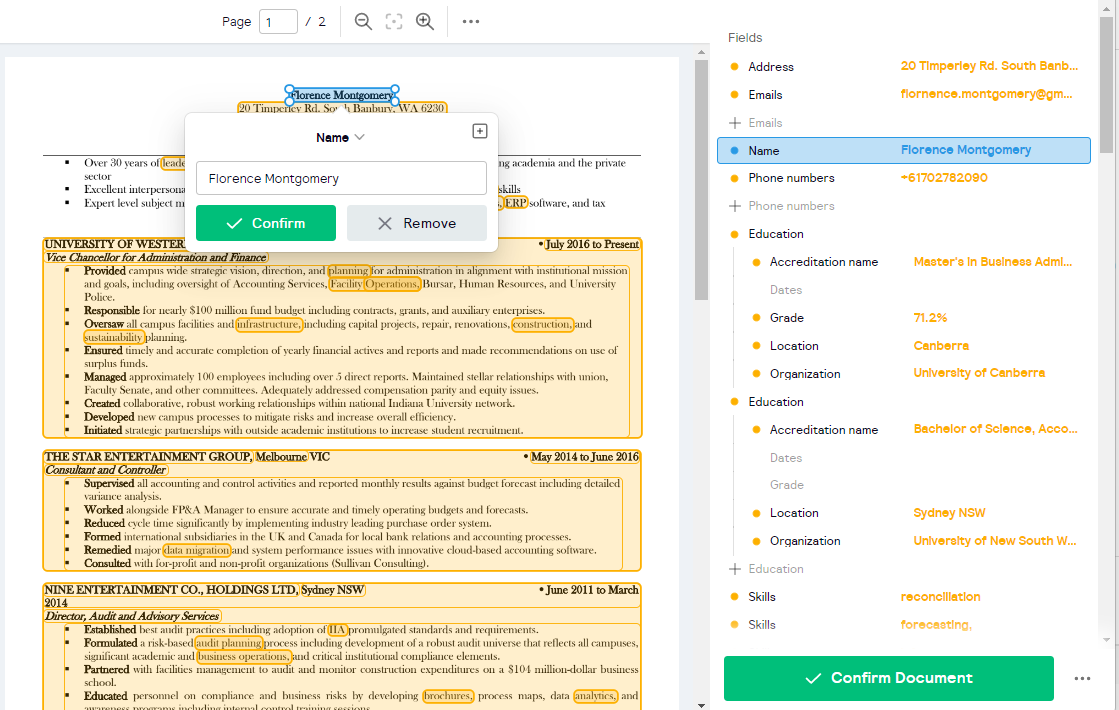
Manual Annotation: In the rare instance where document parsing fails, we've got you covered. You can now annotate documents manually, ensuring that no document is left unattended.
In addition, we've also made some minor tweaks to the overall appearance and layout of the validation tool.
Embedded Users
For those of you embedding the validation interface into your platform, we now offer the flexibility to enable or disable specific actions at an Organization level. To make adjustments to the actions available in the embedded version, simply get in touch with our dedicated support team at [email protected]. We'll be happy to assist you in customizing the tool according to your requirements.