Purpose
Achieving “good enough” (e.g.~80-90% accuracy ) is not enough for mission-critical document processing. Affinda bridges the gap to “excellent” (99%+ accuracy) through our approach, reducing manual work and ensuring top-tier performance. This guide provides an understanding of how Affinda’s information extraction models work and walks users through the steps they can take to uplift the performance of their models. The tutorial covers building high‑quality Model Memory with validated documents, configuring validation settings, adding field descriptions, and troubleshooting low‑performing templates to maximize extraction accuracy.To follow this tutorial, Users should hold Organization Owner or Admin permissions.
Under the Hood: How Affinda Extracts Data
Proprietary Reading Order Algorithms
Proprietary Reading Order Algorithms
This algorithm captures word sequences in visually rich documents in a way that aligns with human comprehension. This ensures that text is processed in the same order a human would read it, leading to more accurate extractions.
Use of Large Language Models
Use of Large Language Models
Selects and utilizes the best-performing LLMs for each task, ensuring optimal results across different document types and structures.
Model Memory with Real-Time Learning
Model Memory with Real-Time Learning
Uses a retrieval-augmented generation (RAG) system to enable continuous improvement. Corrections made in one document are instantly applied to future extractions, eliminating recurring errors without requiring extensive retraining.See Model Memory for more information.
Fingerprinting Algorithm
Fingerprinting Algorithm
Identifies similar documents in Model Memory and provides relevant examples to the model, ensuring highly accurate data extraction and reducing errors.
Benefits of Our Approach
- No extensive model training required – Unlike traditional ML models that require hundreds of training samples, Affinda learns dynamically and applies corrections in real-time. New, high-performing models can be created in a matter of minutes, not weeks.
- Higher accuracy, less manual work – Moving from 95% to 99% accuracy reduces errors by 80%, cutting down the need for human intervention significantly.
- More intelligent than static LLMs – Unlike generic large language models that rely on fixed prompts and lack continuous learning, Affinda actively applies nuanced learning from past interactions to make better decisions.
Steps to Improving Accuracy
Visual Learner? Follow along with our Video Tutorial:1
Upload example documents and validate data to build Model Memory
Affinda’s models use Model Memory to learn from your documents and improve the accuracy of predictions.Affinda intelligently selects a subset of your confirmed documents to use as model memory. These documents act as trusted references, helping the model make more accurate predictions on new, incoming documents.A well-curated model memory is the foundation of highly accurate, automated document extraction.
Why this matters:By following these principles, your model memory will provide a strong foundation for consistent, accurate document processing.Keeping these principles in mind, to build your model memory, upload representative documents.Check the extraction of each field on the document. Correct any errors by redrawing the annotation box over the field on the document. Once the document is completely correct, click ‘Confirm document’.To see how to validate extraction in more detail, see the Validation - Extraction tutorial.
The model will replicate what it learns from model memory. If errors are present, those mistakes will be reproduced in future predictions.
2
Review Model Memory Settings
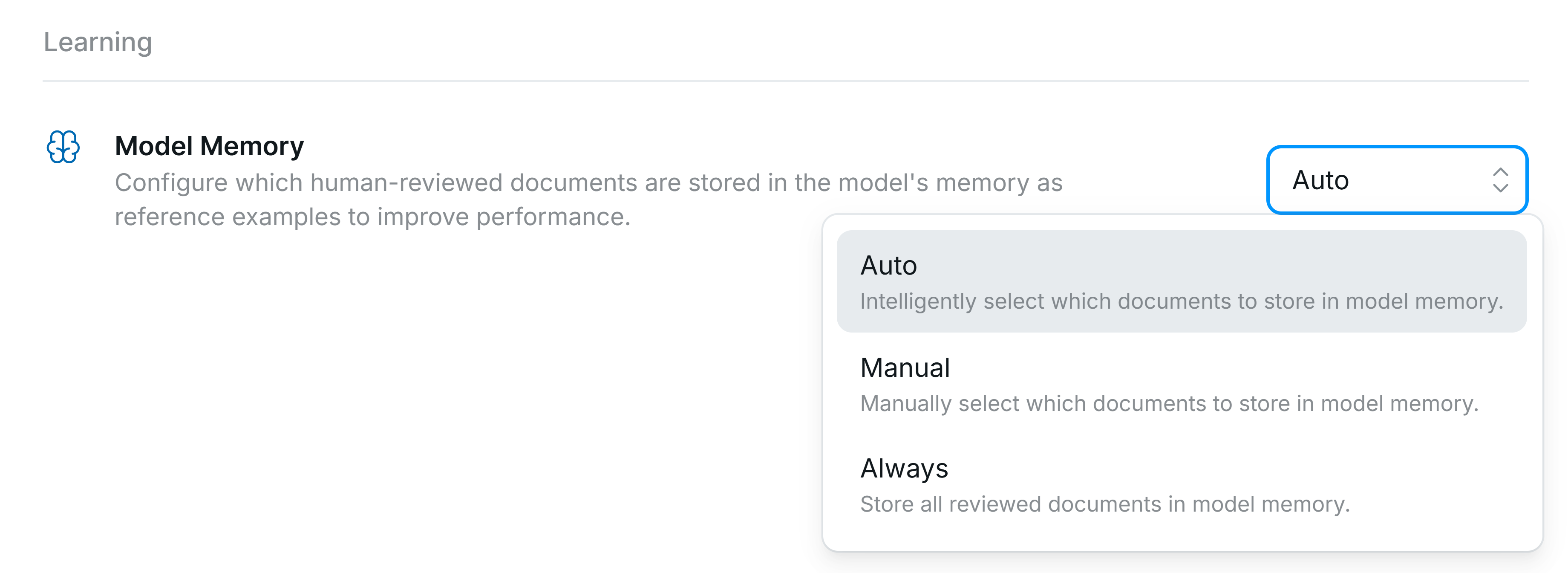
- Auto (Recommended) - Affinda models intelligently select the best documents in your validated set to use as Model Memory. This keeps model memory to a finite set that can be easily audited.
- Manual - No documents from the workspace are automatically added to Model Memory, even after validation.
- Always - Uses every confirmed document as a model memory reference.
3
Review OCR settings
If you are finding that the model is not reading some text on your documents, your OCR settings might not be correct.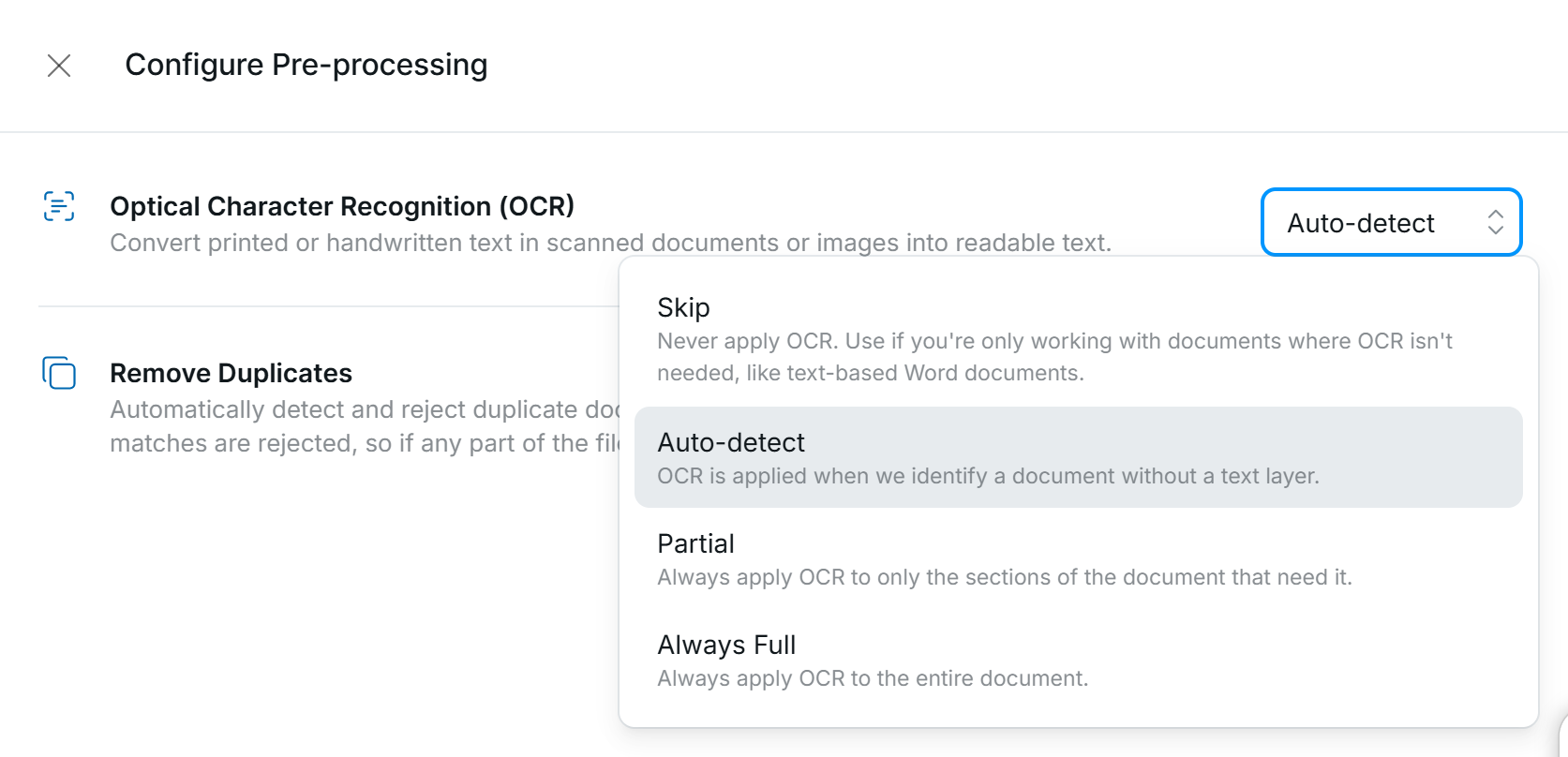
4
Add Field Prompts
If a specific field in your documents is consistently producing inaccurate results, you can improve performance by adding a field prompt.A field prompt allows you to give the model additional instructions for extracting that field. This might include:
- Clarifying the exact information you want.
- Providing counterexamples (what not to extract).
- Explaining the preferred location on the document.
Extract this information from where it is EXPLICITLY stated in the invoice document (e.g. “car stored at”), rather than the address of the person the invoice is addressed to. Do NOT confuse with the address of the supplier. It is better to keep this blank than return an incorrect address.
Descriptions are an advanced aid; the core recommendation remains adding more validated examples to Model Memory for continual improvement.
Troubleshooting low-performing documents
1
Check the Model Memory reference
Go to your document, and click the three dots in the top right corner.Click “Model Memory Reference”.Review the fields on the Model Memory reference. Incorrect extraction on this document could be responsible for incorrect predictions. Make corrections as needed.
2
Add template example
If a high‑volume document template isn’t performing as expected, upload a representative example to Model Memory to boost accuracy.To do this, upload your example document, validate the extracted data, and click ‘Confirm’.Reparse existing documents and check that they are referencing the correct similar example document.
3
Update Model Memory documents
The Model Memory settings found in Workflow settings determine which documents are automatically added once a document is confirmed. However, Organization Admins retain the ability to add or remove documents from Model Memory independent to further control and improve model performance.Documents can be added or removed from Model Memory though the Document List view within a Workspace. This can be applied to a single document, or as a bulk action.