Key Benefits of Model Memory
- Continuous improvement – The model improves over time by referencing validated documents, ensuring better predictions without the need for extensive manual adjustments.
- No need for constant prompt engineering – Instead of adjusting prompts for every case, Model Memory provides a more scalable approach to improving AI performance.
- High accuracy for repeated formats – The system quickly learns and perfects the extraction for recurring document formats, such as invoices from a particular supplier.
How It Works:
- When a new document is uploaded, Affinda’s Fingerprinting algorithm scans Model Memory to find sufficiently similar documents.
- If relevant documents are found, one or more of these validated examples are provided to the model.
- The model uses these documents to improve extraction accuracy and consistency.
Managing Model Memory
Options for automatically adding documents to Model Memory
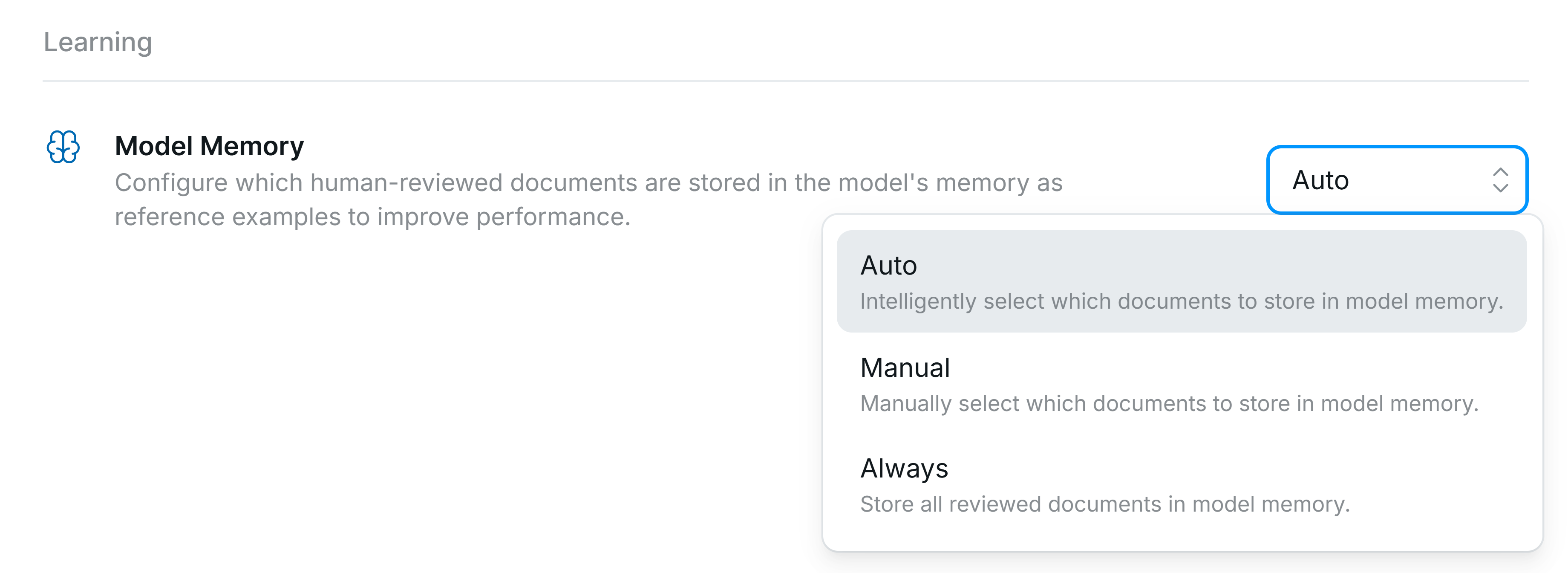
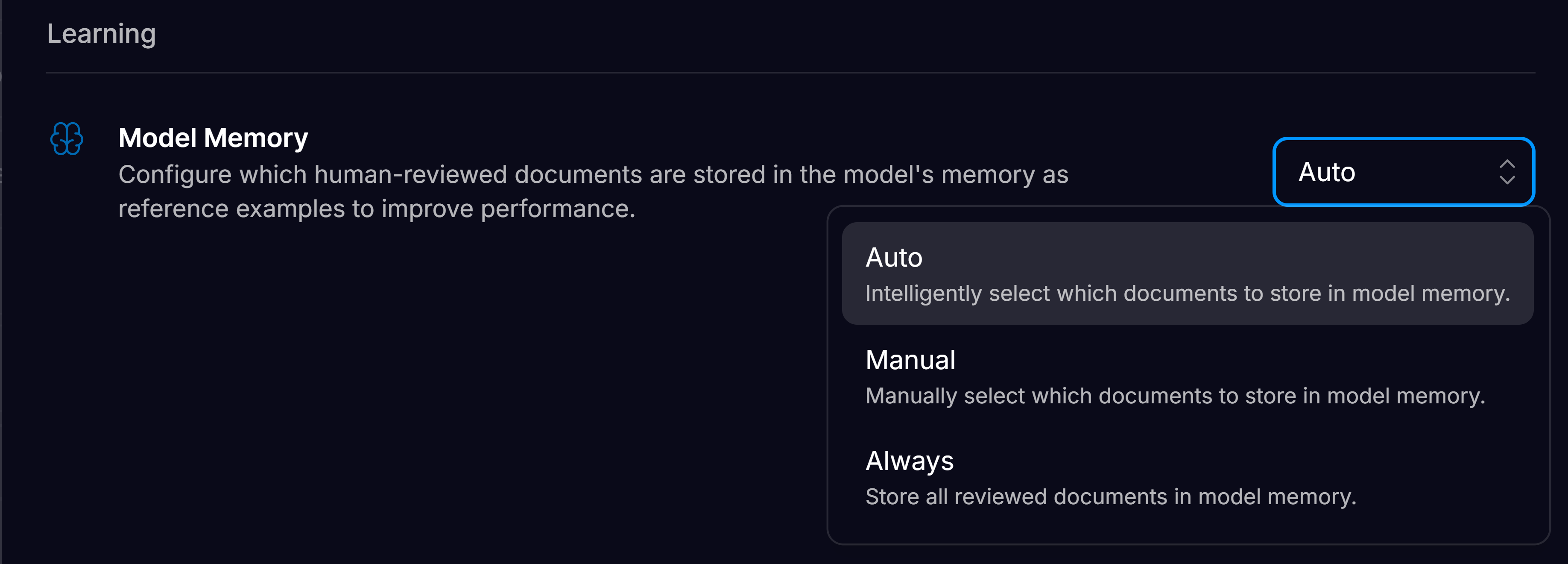
- Auto (Default Option) – Affinda intelligently selects which documents are added.
- Manual – No documents from the workspace are automatically added to Model Memory, even after validation.
- Always – Every validated document from the workspace is added to Model Memory.
- The memory does not grow excessively large, making it easier to audit.
- The model remains efficient by avoiding redundant examples of well-represented formats.
Manually updating documents in Model Memory
The above setting determines which documents get added to Model Memory when they are Confirmed. However, Organization Admins retain the ability to add or remove documents from Model Memory independent of this setting. This provides a mechanism for users to further control and improve model performance. Documents can be added or removed from Model Memory though the Document List view within a Workspace. This can be applied as an action on a single document, or as a bulk action.Importance of Highly Accurate Data in Model Memory
Since Model Memory directly references individual documents and their validated data, the accuracy of annotated documents is critical. Incorrect or low-quality annotations can lead to:- Confusion in model predictions – The model may reference incorrect information, leading to erroneous outputs.
- Propagation of mistakes – Since Model Memory applies learnings from past documents, any errors will be replicated in future extractions.
Re-parsing after adding Model Memory documents
Once you add more documents to your model memory, the model learns from them and can make better predictions on similar examples in the future. Affinda will automatically identify documents that could benefit from this improved accuracy. For these documents, the Reparse button in the Document Validation View will turn orange, indicating that the model recommends you reparse the document to take advantage of the new learnings.If accuracy drops on a document type that was previously extracting well, the first thing to check is the Model Memory reference. From the Document Validation interface:
- Click the three-dot icon in the top right corner
- Select Model Memory Reference to view the confirmed document the model used as its reference.
Frequently Asked Questions about Model Memory
How can I see what model memory document was referenced?
How can I see what model memory document was referenced?
The user can see the model memory document referenced in each new document processed by clicking on the three dots in the left-hand corner of the Document Validation Interface, then selecting ‘Model Memory Reference’. This will open the confirmed document used by the model in prediction extractions. Users can make corrections to the reference document in this view.
Does a bigger model memory help my model performance?
Does a bigger model memory help my model performance?
Yes. In Affinda, Model Memory works like a living reference library: every document you validate is stored and later surfaced by the fingerprinting algorithm to guide new extractions. The more high-quality, diverse documents you keep in that memory, the greater the chance the model finds a close match and pulls the right examples, so accuracy improves without retraining.Just make sure the memory grows with relevant and correctly annotated files—Affinda’s recommended “Auto” mode keeps only representative samples so the memory doesn’t become bloated with duplicates, which could reinforce errors.
My Model Memory Document has incorrectly validated data, what do I do?
My Model Memory Document has incorrectly validated data, what do I do?
If you spot a mistake in a document that’s already sitting in Model Memory, it’s important you correct it promptly. Locate the document under the confirmed documents tab and open the Document Validation UI. Adjust the wrong annotations (drag them to the right spot or redraw them) and then click “Confirm Document”.Now you have corrected the error; you should re-parse any documents in the “For Review” tab to reapply the extraction model and prevent the propagation of mistakes.