Detailed Tutorial for Validating Classification
Reviewing Splitting and Classification
Click here for Affinda Academy tutorial
Configuring Classification
Classification behavior can be configured in the Workspace Settings. The classification model will assign a classification from the set of document types configured in your workspace.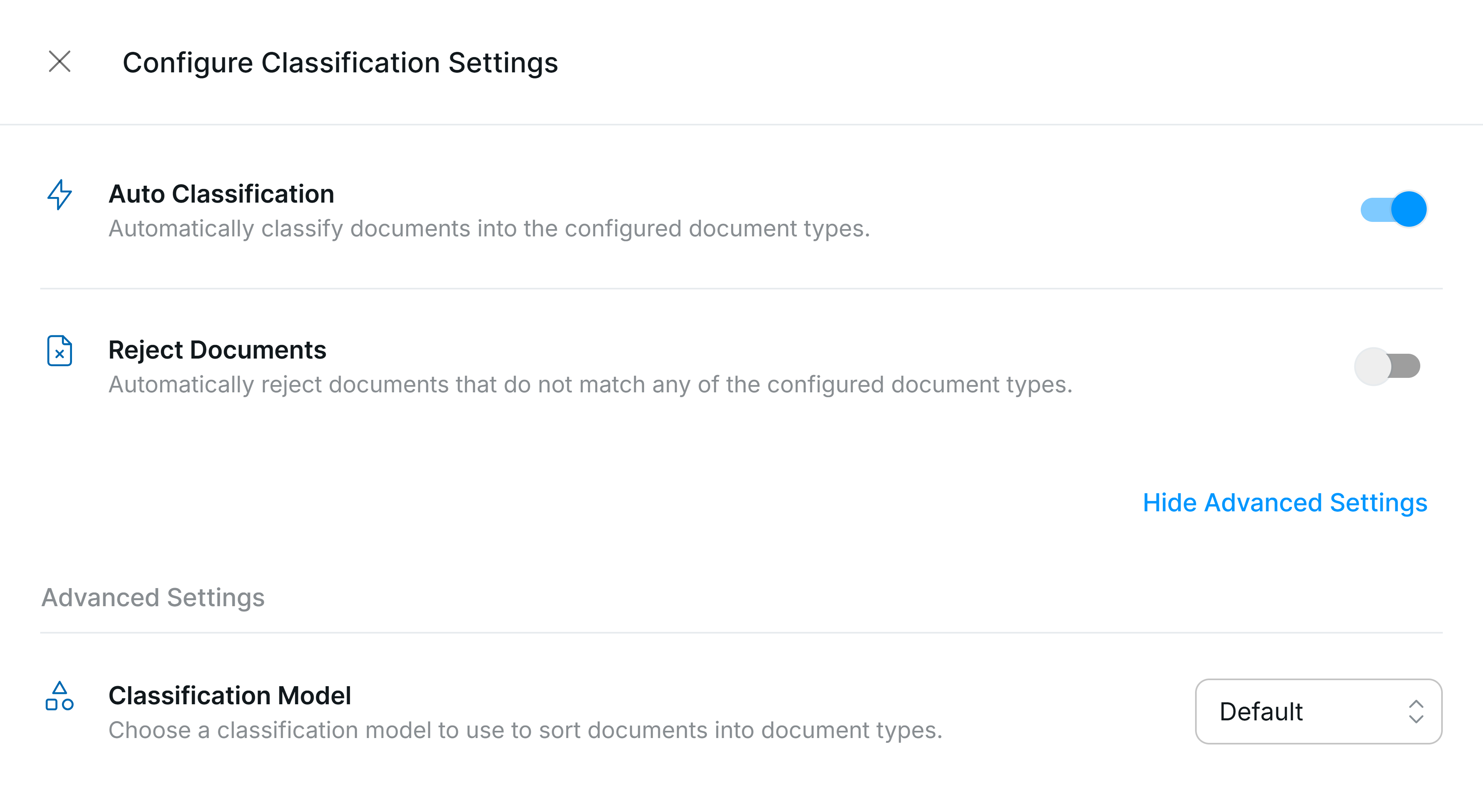
Auto Classification
When enabled, Affinda will classify and route each document to the relevant Document Type when uploaded to a Workspace. If the document is uploaded to a specific Document Type, Affinda will not attempt to re-classify automatically. If disabled, documents sent to a Workspace will remain unclassified until updated by a user.Reject Documents
Workspaces can be configured so that Affinda automatically rejects documents that are not of the right type. These documents will be sent to the ‘Rejected’ list in the app, where they can be reviewed and moved to the appropriate Document Type by a user. Document rejection will occur in the following cases:- If a document is sent to a Workspace and no relevant Document Type is found within the Workspace
- If a document is sent to a specific Document Type, and the classification the model returns does not match the Document Type
Default Classification Model
The default classification model is a self-learning system that improves over time. When a new document is uploaded and needs to be classified, the model uses two key inputs:- Document Type Names and Descriptions The names and descriptions provide the model with an understanding of the general characteristics and unique traits of each Document Type.
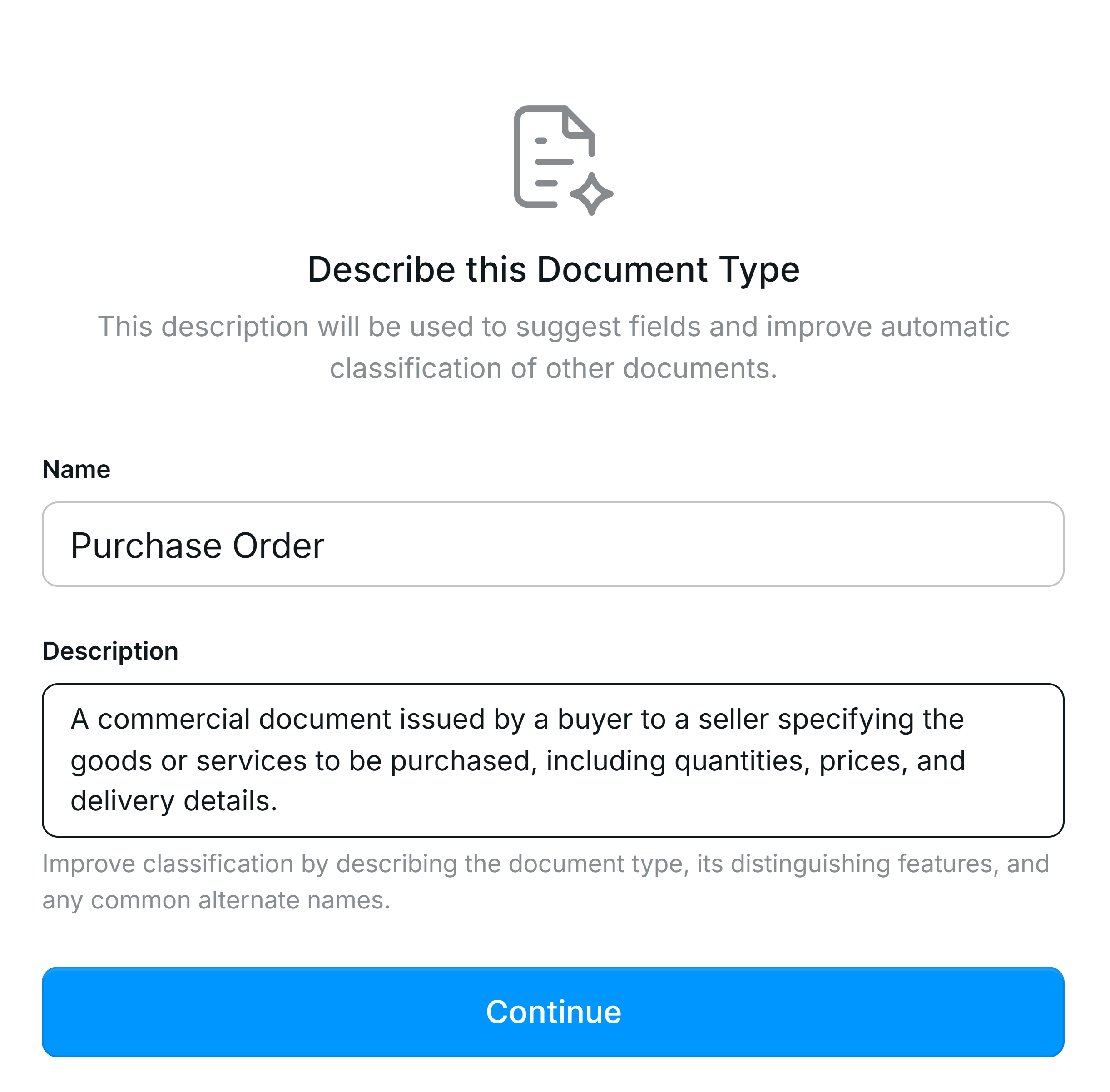
- Reference Documents from Model Memory The Model Memory offers examples of previously confirmed documents, helping the model identify patterns and similarities. See Model Memory page for more information.
Fast Classifier for Resume Parser customers
This non-learning model is optimised for performance on Resumes and Job Descriptions in particular and is the default classifier used for all customers with a Recruitment Technology use case.Custom Classification Model
For customers with bespoke requirements that the above options do not meet, the Affinda team can create a custom classification model. Get in touch with the Affinda team to learn more about this option.