OCR Options
Affinda provides four different options for customers that dictate whether OCR is applied to each document. While applying OCR on documents can increase overall performance, it adds additional processing cost and time (0.5 - 1 seconds per page), so applying OCR might not be suitable for all use cases. By default, new Workspaces will have ‘Auto-Detect’ OCR enabled.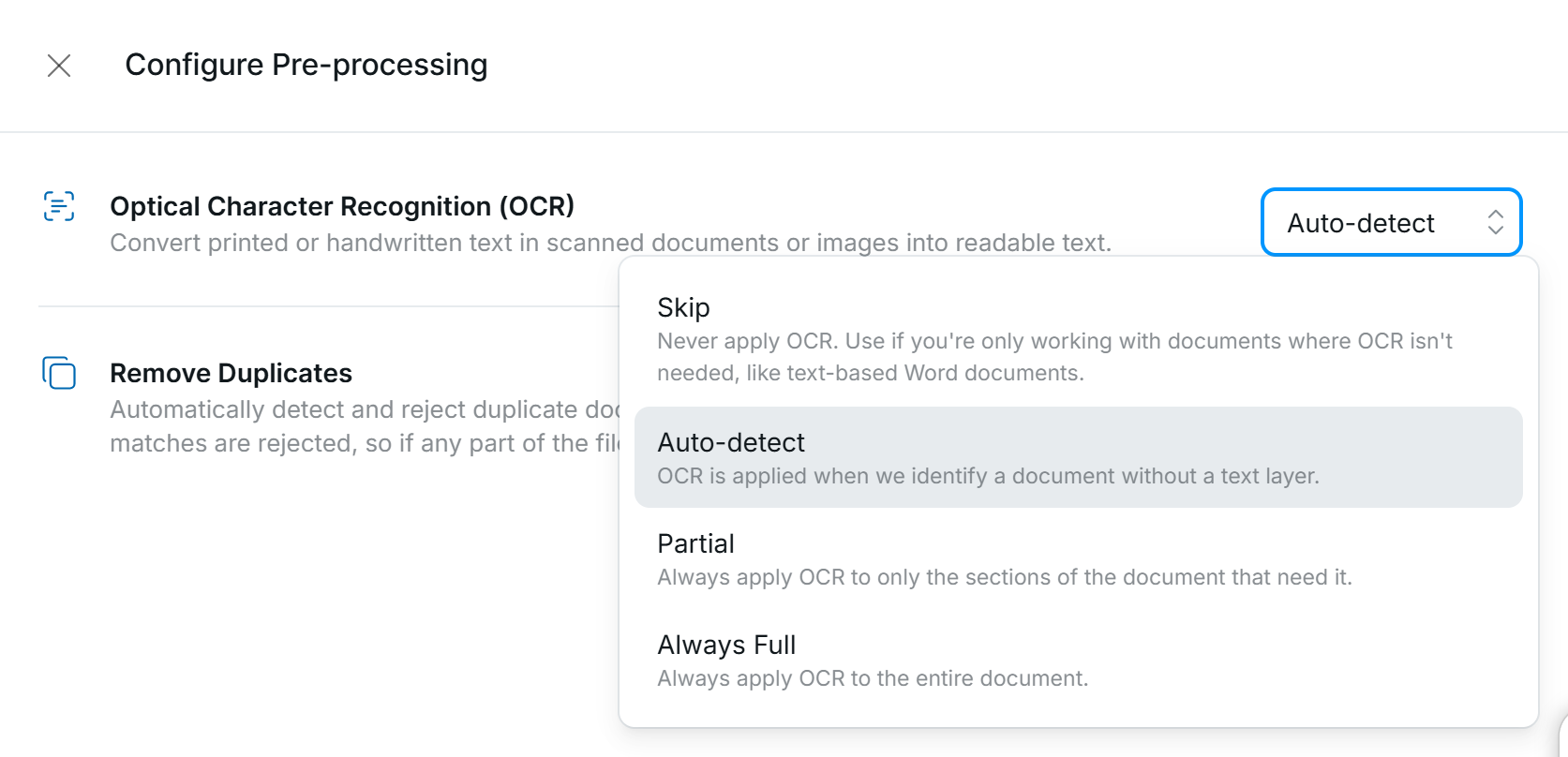
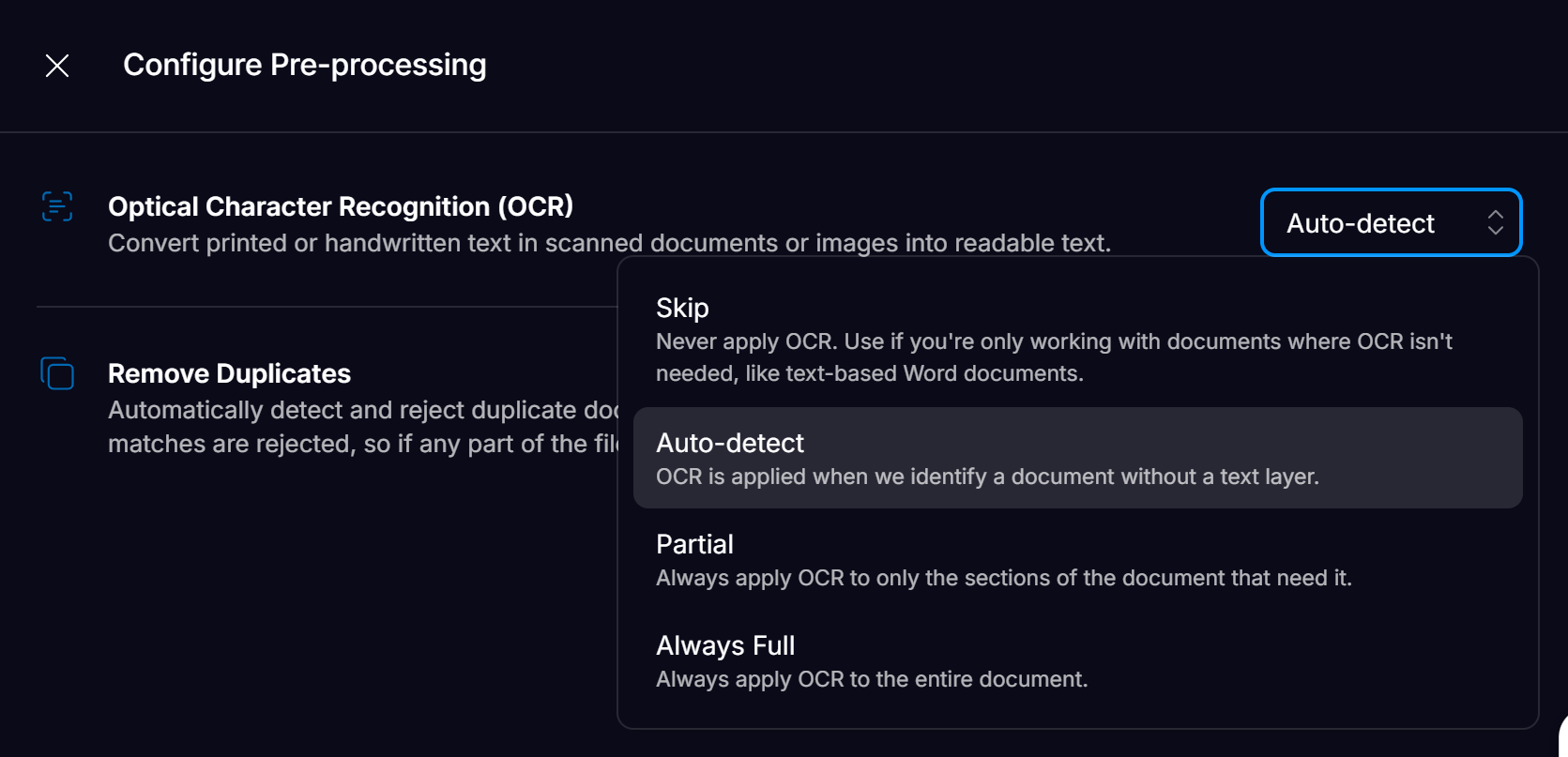
Skip
OCR is never applied, even if no text layer is found. Suitable for use cases where speed/cost is most important. Not recommended for most use cases.
Auto Detect (recommended)
Applied to documents where no text layer is found within the document. Affinda will apply OCR over the entire document if fewer than 25 words are in the text layer of the document. The text extracted from the document will overwrite any existing text layer. If a text layer with over 25 words is found, OCR will not be applied.
Partial
OCR is applied to elements of the document without a text layer to all documents uploaded. This preserves the original machine-readable text but also extracts additional information from images and pages in the document without this text layer.A typical example is an invoice where the supplier name and business number are contained within the header image/logo. Combining both the text layer and OCR-extracted text ensures comprehensive results.
Always Full
OCR is applied to all documents and is used in place of any existing machine-readable text layer. Typically, only recommended when the text layer in a document is frequently incorrect and needs to be corrected.
What if the text layer on a document is incorrect?
From time to time, a document may be submitted that has a text layer that does not perfectly match the data in the document itself. Whilst this is uncommon, it means that Affinda has not applied OCR technology and thus we will not be able to accurately extract the data. In the rare cases where this occurs, users can click the three-dot icon in the top right corner of the Document Validation interface and click ‘Apply OCR, ’ which will apply OCR to the document and re-parse the data.