Importance of Pre-Processing
By ensuring documents are well-prepared before extraction, pre-processing- Reduces the likelihood of errors in later stages
- Improves the speed and accuracy of data extraction
- Enables the seamless handling of various document types and formats
Key Pre-processing Actions:
- Invalid File Handling: Identify issues that mean a document cannot be processed, such as insufficient text in the document, unsupported file types, corrupted files, or password-protected documents.
- File Format Conversion: This involves converting file formats (e.g., images, PDFs with embedded data) into a PDF format suitable for processing.
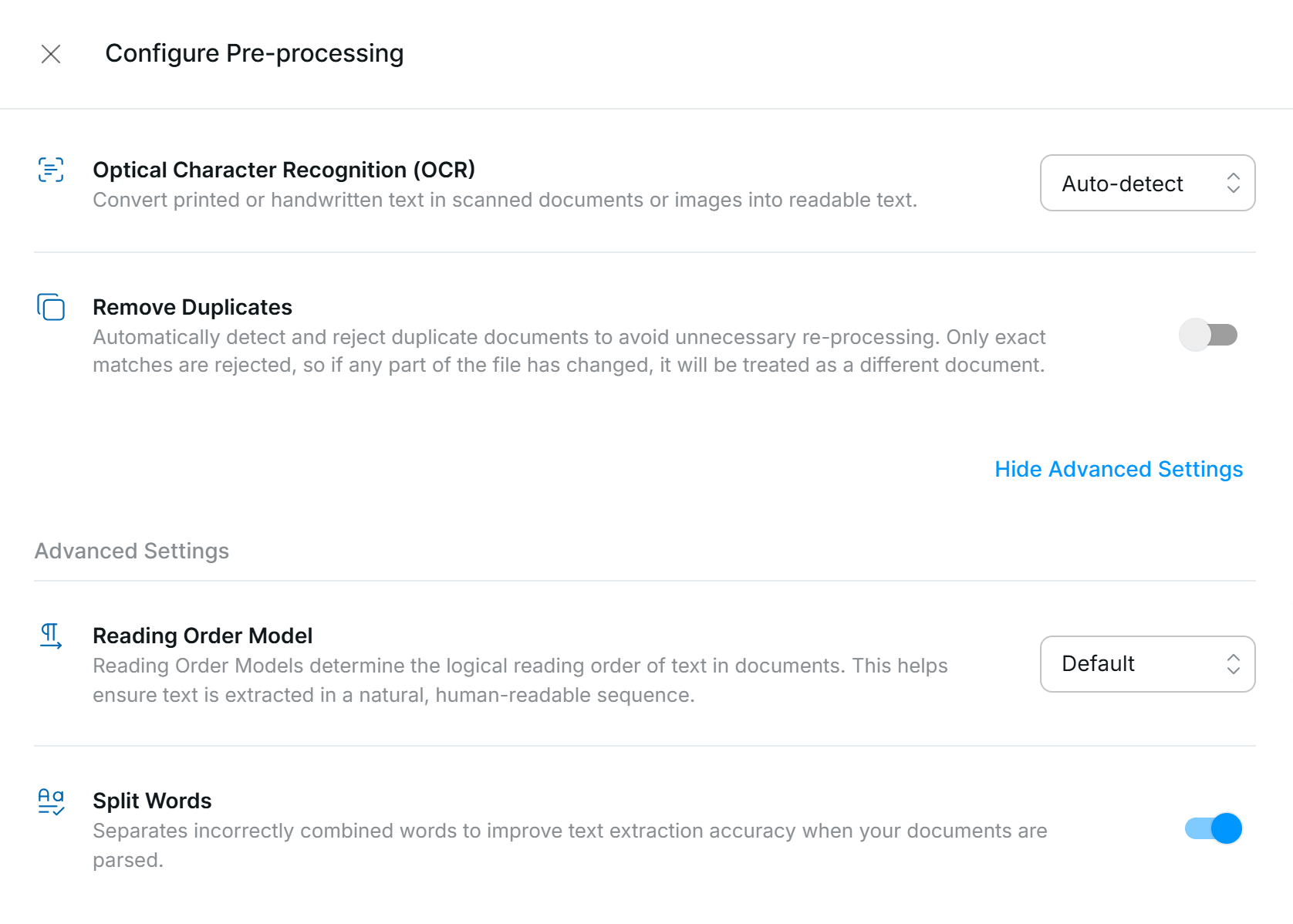
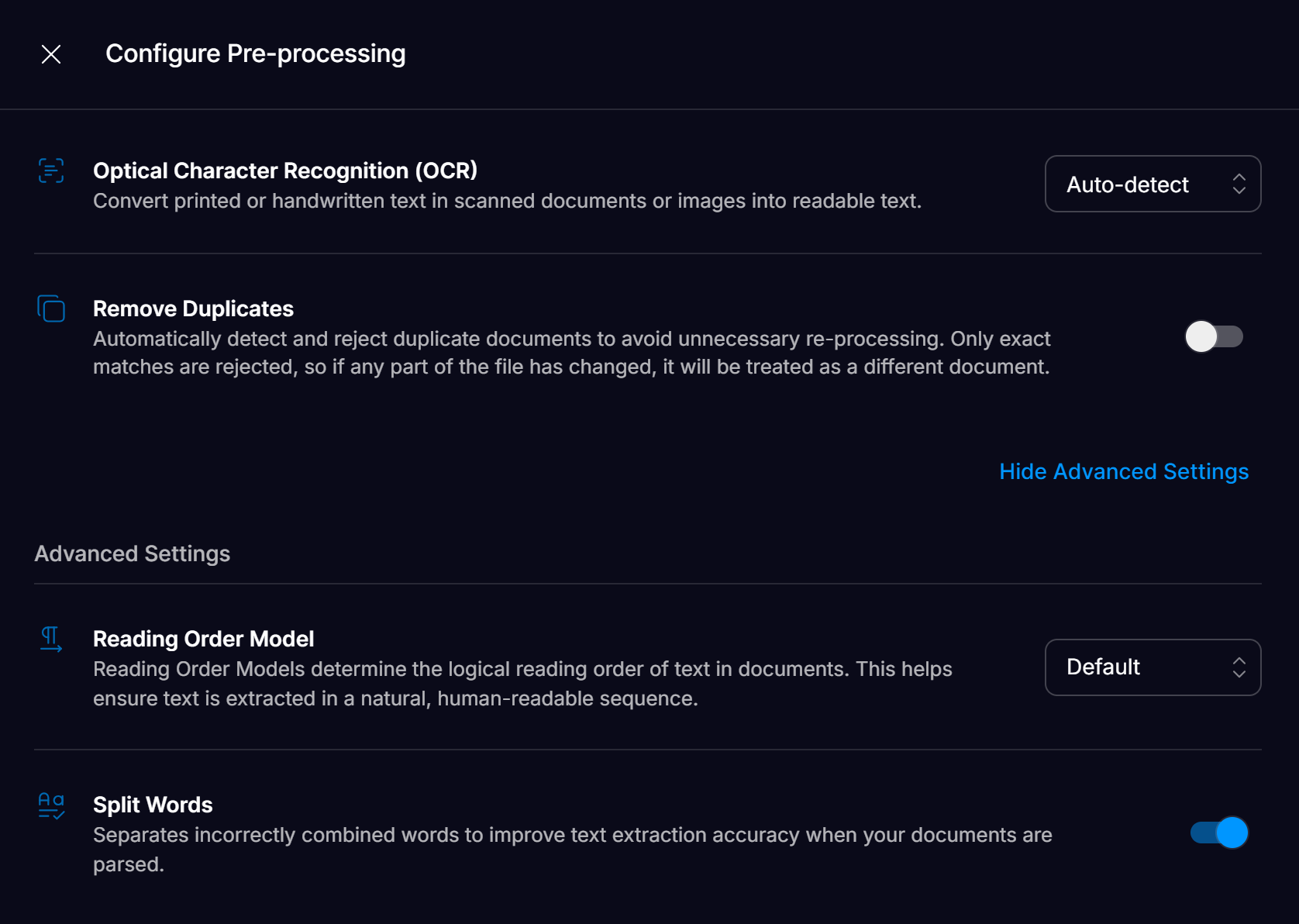
- Remove Duplicates: Workspaces can be configured to identify and reject documents that have already been processed. This can be configured by the user in Workflow Settings; see Remove Duplicates for more information.
- OCR (Optical Character Recognition): Extracting text from scanned or image-based documents using advanced OCR technology, ensuring high accuracy for all document types and formats. See OCR and Text Extraction for more information.
- Language Detection: Automatically identifies the language of the document to ensure high-accuracy extraction.